Descriptor API¶
The Descriptor API is one of the main component of the Plums plot user interface.
A Descriptor is a component which describes a set of Record by adding special attributes
(actually properties) which, when coupled with the Descriptor schema,
allows external components to get personalized data on a Record in a unified manner and without any prior on the
Record content.
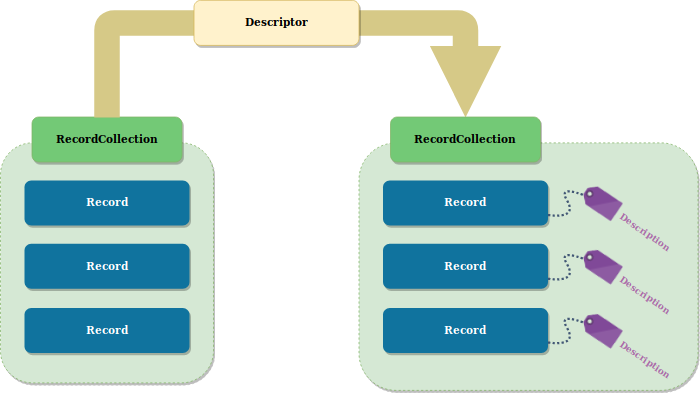
A Descriptor is made of 3 parts:
An
update()method which updates internal values given a collection ofRecordCollection.A
compute()method which writes special description properties onRecordin a collection ofRecordCollectionaccording to the previously accumulated internal values.A
__descriptor__()attribute which exposes pointers on how to decode the written out description properties.
There are 2 types of descriptor:
CategoricalDescriptorwhich writes a category index on eachRecordand exposes the mapping as its schema.ContinuousDescriptorwhich writes a real quantity on eachRecordand exposes the possible range as its schema.
Hint
The ColorEngine which is part of the Plums plot developer API is itself a Descriptor which writes
a Color on each Record and acts as either a continuous or a categorical descriptor according to the set of
Descriptor it wraps.
Plums plot comes with a collection of factory-designed descriptors, however the use of Descriptor allows
users to seamlessly personalize the way Color are computed in a plot figure as well as the information plot in the
tag alongside each geometry by creating new Descriptor.
Example: The Letter descriptor¶
Let us consider the following RecordCollection to be plot:
from plums.commons.data import RecordCollection, Record
# Create records
records = [
Record(
[[[100, 100], [100, 150], [150, 150], [150, 100], [100, 100]]],
['Car'], confidence=0.9),
Record(
[[[710, 100], [710, 150], [760, 150], [760, 100], [710, 100]]],
['Bus'], confidence=0.857),
Record(
[[[500, 500], [550, 550], [500, 600], [450, 550], [500, 500]]],
['Boat'], confidence=0.72),
Record(
[[[250, 0], [300, 0], [275, 25], [300, 50], [250, 50], [275, 25], [250, 0]]],
['Car'], confidence=0),
Record(
[[[300, 300], [320, 280], [420, 380], [400, 400], [300, 300]]],
['Car'], confidence=0.3),
Record(
[[[650, 300], [670, 280], [770, 380], [750, 400], [650, 300]]],
['Bus'], confidence=0.1),
Record(
[[[-20, 600], [50, 600], [50, 650], [-20, 650], [-20, 600]]],
['Car'], confidence=0.927),
Record(
[[[700, 600], [800, 600], [800, 650], [700, 650], [700, 600]]],
['Bus'], confidence=0.927),
Record(
[[[500, -50], [550, -50], [550, 50], [500, 50], [500, -50]]],
['Boat'], confidence=0.5647),
Record(
[[[500, 750], [550, 750], [550, 850], [500, 850], [500, 750]]],
['Boat'], confidence=0.1763),
]
# Create collection
records_collection = RecordCollection(*records)
The built-in collection of Descriptor already allows to select the main color according to each Record’s
Area, Labels or Confidence, but what if we wanted to select the main color according to the first
labels first letter ?
The solution is to create a new tailor-made descriptor to handle the task and pass the result to the ColorEngine to
use.
To make a descriptor we must subclass the Descriptor abstract base class or one one of its generic subclass like
CategoricalDescriptor or ContinuousDescriptor.
In this example, we will start from the barest possible case and subclass Descriptor, however we might have been
able to save ourselves a bit of slack by subclassing CategoricalDescriptor which already have a significant portion
of machinery already laid out.
from plums.plot.descriptor import Descriptor
class Letter(Descriptor):
def __init__(self):
# Here we will store each known letter's index
self._indices = []
# Here we will store each known letter
self._letters = []
# Here we will store the maximum known index for convenience
self._max = -0.5
super(Letter, self).__init__(name='letter')
def reset(self):
"""Reset the lists of letters and indexes to empty lists."""
self._indices = []
self._letters = []
self._max = -0.5
def update(self, *record_collections):
"""Update the lists of letters and indexes."""
for record_collection in record_collections:
for record in records_collection:
letter = str(record.labels[0])[0]
if letter in self._letters:
# If we have seen this letter before, we pass on
continue
# Otherwise, we must update the lists of letters and indexes.
self._max += 1.0
self._letters.append(letter)
self._indices.append(self._max)
def compute(self, *record_collections):
"""Add the description property according to the letters and indexes lists."""
for record_collection in record_collections:
for record in records_collection:
letter = str(record.labels[0])[0]
if letter not in self._letters:
raise ValueError('Unknown letter {}:'
'Expected one from {}'.format(letter, self._letters))
setattr(record,
self.property_name,
self._indices[self._letters.index(letter)])
return record_collections
def _make_interface(self):
"""Construct the missing parts of the __descriptor__ dictionary."""
return {
'type': 'categorical',
'schema': {letter: index
for letter, index in zip(self._letters, self._indices)}
}
Let’s break it down:
We begin by declaring a new class inheriting from
Descriptorto which we add internals as attributes:class Letter(Descriptor): def __init__(self): # Here we will store each known letter's index self._indices = [] # Here we will store each known letter self._letters = [] # Here we will store the maximum known index for convenience self._max = -0.5 super(Letter, self).__init__(name='letter')
We then need to override the
update()method which will update these internal attributes according to the letters encountered in eachRecordCollection:def update(self, *record_collections): """Update the lists of letters and indexes.""" for record_collection in record_collections: for record in records_collection: letter = str(record.labels[0])[0] if letter in self._letters: # If we have seen this letter before, we pass on continue # Otherwise, we must update the lists of letters and indexes. self._max += 1.0 self._letters.append(letter) self._indices.append(self._max)
Following from there, we also override the
compute()method which does the inverse mapping and adds an index according to the letters found in eachRecordCollection:def compute(self, *record_collections): """Add the description property according to the letters and indexes lists.""" for record_collection in record_collections: for record in records_collection: letter = str(record.labels[0])[0] if letter not in self._letters: raise ValueError('Unknown letter {}:' 'Expected one from {}'.format(letter, self._letters)) setattr(record, self.property_name, self._indices[self._letters.index(letter)]) return record_collections
Last but not least, we construct the corresponding
__descriptor__with the_make_interface()private method:def _make_interface(self): """Construct the missing parts of the __descriptor__ dictionary.""" return { 'type': 'categorical', 'schema': {letter: index for letter, index in zip(self._letters, self._indices)} }
When put all together, we get a valid categorical descriptor which may be used in plot:
>>> plot = StandardPlot(Letter(), plot_tag=Labels(), fill=True)
>>> plot.add(data_point.tile, data_point.annotation.record_collection)
>>> plot.plot()
